

Deduplication Demystified: Navigating duplicates in Event-Driven Systems


Introduction
When working with streaming queues such as Google Cloud Pub/Sub or Apache Kafka, ensuring data integrity is paramount. These platforms provide "at least once" delivery semantics, meaning that a message may be delivered to the consumer more than once in case of network issues or failures. This characteristic introduces the possibility of duplicate messages in your streaming pipeline.
Deduplication becomes a crucial aspect of managing streaming data to maintain data consistency and prevent unintended processing of duplicate information. This tutorial will guide you through the process of deduplicating data pulled from Google Cloud Pub/Sub using Redis, a highly efficient in-memory data store.
Step 1: Set up Google Cloud Pub/Sub
Create a Pub/Sub Topic and Subscription:
Open the Google Cloud Console.
Navigate to the Pub/Sub section.
Create a new topic (e.g., "deduplication-topic").
Create a subscription to the topic.
Step 2: Set up Cloud Memorystore (Redis)
Create a Memorystore Instance:
Open the Google Cloud Console.
Navigate to the Memorystore section.
Create a new Redis instance.
Note down the connection details (host and port) provided by Memorystore.
Step 3: Install Required Libraries
pip install google-cloud-pubsub
pip install redis
Step 4: Python Consumer Script
import redis
import os
import logging
from google.cloud import pubsub_v1
from concurrent.futures import TimeoutError
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
project_id = "upgradlabs-1695429673270"
subscription_name = "redis-test"
redis_host = "10.141.198.99"
redis_port = 6379
# Set the environment variable to the path of your service account key file
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "key.json"
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project_id, subscription_name)
redis_client = redis.StrictRedis(host=redis_host, port=redis_port, decode_responses=True)
def callback(message):
try:
# Print the received message
logger.info("Received message: %s", message.data)
# Check if the message is a duplicate
if redis_client.sismember("deduplication_set", message.data.decode("utf-8")):
logger.info("Duplicate message: %s", message.data)
else:
# Process the message
logger.info("Processing message: %s", message.data)
# Add message to the deduplication set
redis_client.sadd("deduplication_set", message.data.decode("utf-8"))
except redis.RedisError as redis_error:
logger.error("Redis Error processing message: %s", redis_error)
except Exception as e:
logger.exception("Error processing message: %s", e)
finally:
# Acknowledge the message to remove it from the queue
message.ack()
# Subscribe to Pub/Sub with detailed logging
try:
logger.info("Subscribing to %s...", subscription_path)
future = subscriber.subscribe(subscription_path, callback=callback)
try:
# Wait for the subscription to be ready
future.result(timeout=100000)
logger.info("Subscribed successfully to %s", subscription_path)
# Keep the script running to continuously listen for messages
while True:
pass
except TimeoutError:
logger.info("No messages received within the timeout period. Exiting.")
except KeyboardInterrupt:
logger.info("Subscriber stopped.")
except Exception as e:
logger.exception("Error in subscription: %s", e)
finally:
# Close the Redis connection when done
redis_client.close()
Step 5: Redis Sets for Deduplication
In this tutorial, we leverage Redis sets to efficiently handle deduplication. Redis sets are a collection of unique elements, and they provide the perfect data structure for managing deduplication efficiently.
How Redis Sets Work for Deduplication
When a new message is received, the consumer checks whether the message is a duplicate by using the
sismemberfunction of Redis sets.If the message is already present in the set, it is identified as a duplicate and not processed further.
If the message is not present, it is considered unique, and it is processed and added to the Redis set using
saddto ensure future duplicates are identified.
Redis Sets vs. Bloom Filters
Redis Sets*: A Redis set stores any given value only once. No matter how many times a value is added to a set, the set contains only one copy of that value. Redis sets are also optimized to answer the question, “Is this value in this set?” with extreme speed. Sets are also determinate in that the answers to the question are “Definitely” and “Definitely not.” Be aware, however, that a set can use a substantial amount of memory as the number of unique values in the set increases.*

Bloom filters are another data structure often used for deduplication.
Bloom filters: The Probabilistic module provides Bloom filters, a probabilistic algorithm useful for deduplication. Unlike a set, a Bloom filter only stores hashes for each value, not the value itself. That means a Bloom filter can take as little as 2% of the memory a set requires. And they are typically slightly faster than sets, which are themselves very fast. But there is a tradeoff for this speed and memory efficiency: a Bloom filter is not determinate. The answers to the question, “Have we seen this value before?” are “Definitely not” and “Probably so.” In other words, false positives are possible with a Bloom filter.

Accuracy: Redis sets offer superior accuracy. While Bloom filters can have false positives (indicating a message is a duplicate when it's not), Redis sets guarantee accuracy in deduplication.
Space Efficiency: Bloom filters can be more space-efficient but at the cost of potential false positives. In situations where accuracy is critical, as is often the case in deduplication, the reliability of Redis sets is preferred.
Here is some detailed information comparing sets and bloom filters: Fast and Scalable Data Deduplication Solutions | Redis
Deduplication Process
Initial Run:
- Posting an initial set of messages titled "Entry 1", "Entry 2", "Entry 3", "Entry 4", and "Entry 5" once to show how the consumer processes these unique messages.
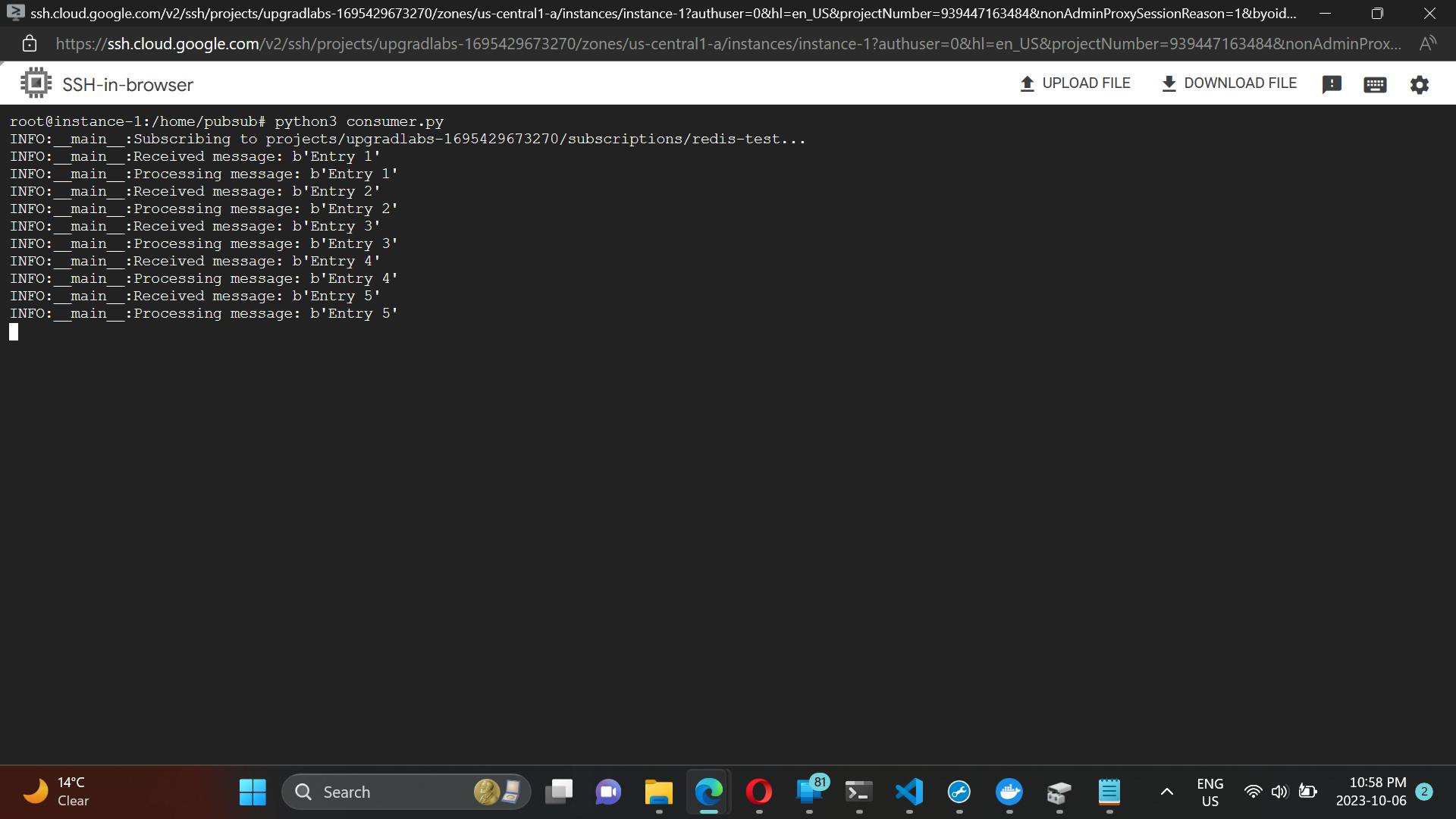
Subsequent Runs:
- Posting "Entry 2" and "Entry 4" multiple times to demonstrate the deduplication process in our consumer

* Observe that the consumer identifies and logs duplicate messages, preventing them from being processed again.
Conclusion
Redis can be leveraged to craft scalable and dependable systems within event-driven platforms, simplifying deduplication and bolstering overall reliability in the dynamic landscape of event-driven architecture.